

ごきげんよう。災害級の暑さの中で約100kmのサイクリングをしても日焼けせずに済んだ、備えあれば憂いなしがモットーのgonzoです😺
さて、皆さんは正規表現(Regular Expression)というのをご存じでしょうか?
初耳の方や「聞いたことはあるけどよく知らないなぁ🤔」という方が多いのではないかと思います。
今回はその正規表現の概要や使い方例をご紹介したいと思います。
正規表現とは?

文字列の集合を一つの文字列で表現する方法の一つである。
Wikipediaにはこう書かれていますが、これだけではイメージが湧きにくいと思います。
具体的な例を挙げると、下記の様な文字列を使って対象のテキストデータから検索や置換する事ができるのが正規表現です。
|
1 2 |
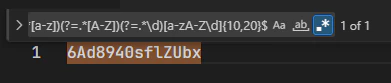
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{10,20}$ |
このような文字列はパターンと呼ばれたりします。
初見の方はさっぱり意味が分からないかと思いますし、ましてや正規表現というのは専らIT系エンジニアが利用しているケースが多いので、特殊技能の一種だと思われがちかもしれません。
しかしながら、普段パソコンでテキスト編集の作業をしているような多くの人に有益であり、誰もが知っておいて損は無いものなんです。
正規表現に対応したエディタ
テキスト編集で正規表現を利用するには対応したテキストエディタが必要です。著名なエディタは当たり前のように対応しており、Windowsならば秀丸エディタ、Visual Studio Code、サクラエディタ、EmEditorなど軒並み使えるようになっています。Excelなどテキストエディタ以外のアプリケーションでも対応しています。
本記事では、筆者推しの飛ぶ鳥を落とす勢いで進化し続けているVisual Studio Codeを使用した例をご紹介していきます。
正規表現検索の例
以下の内容の対象テキストデータを例にとって、正規表現検索の使い方をいくつか解説します。
|
1 2 3 4 |
りんご,ごりら,らっぱ ぱせり,りんご,ごりら らっぱ,ぱせり,りんご |
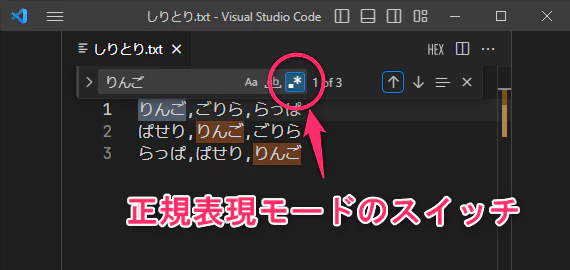
ちなみにVisual Studio CodeではCtrl + Fで検索窓が開きます。
そのままだと通常検索ができますが、右のアスタリスクのアイコンをクリックすると、正規表現モードになります。
行の始まりと終わりにある文字列を探す
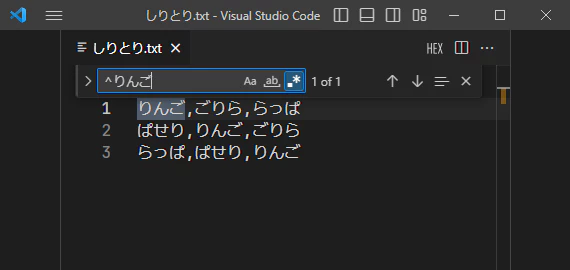
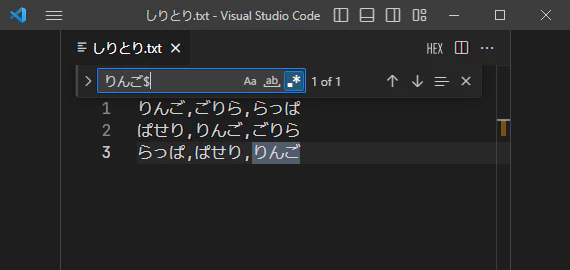
正規表現では、行の始まりは^で、行の終わりは$といった記号で表す事ができます。
例えば、りんご の文字列を検索したい時、行頭にあるものは ^りんご で検索し、
行末にあるものは りんご$ で検索することが出来ます。
このように、実際の文字ではないものを抽象的に表現する記号をメタ文字と言います。
任意の文字を探す
先のしりとりテキストにおいて、中央列にある りんご を検索したい時、普通の検索では ,りんご,といった具合に前後にカンマを含めれば検索できますよね。
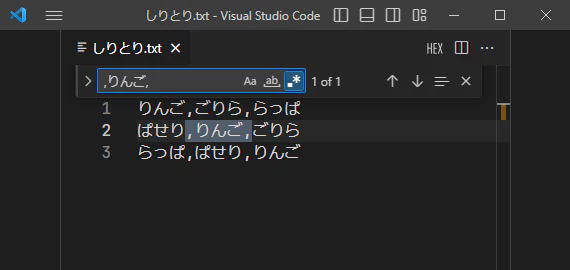
しかし、りんご以外も含めた中央列にあるもの全部を検索したい場合はどうしたらいいでしょう?
そこで登場するのが任意の文字のメタ文字である.です。
もし、ドットそのものを検索したいときは『\.』と書くんだニャー
ちなみに、画面には表示されていませんが、行の折り返しには改行文字(\n)が存在し、これは任意の文字には含まれないようになっています。
ということで、今回のしりとりに使われている単語はみんな3文字なのでりんごをドット3個に置き換えて,...,とすると全部ヒットします。
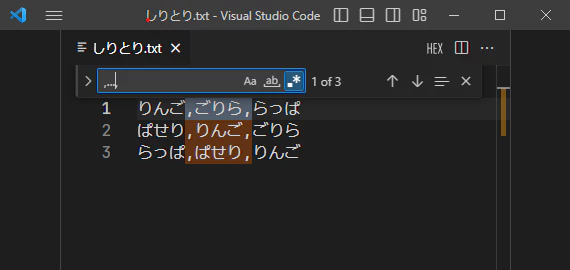
長さが異なる単語にもヒットさせる
さて、これまでに登場している単語はすべて3文字だったので、.を3個連続で置けば解決しました。しかし、3文字以外の単語にも対応が必要な場合も出てくるでしょう。
そうするには1回以上の繰り返しを表す+使い、,.+,を検索文字列とします。
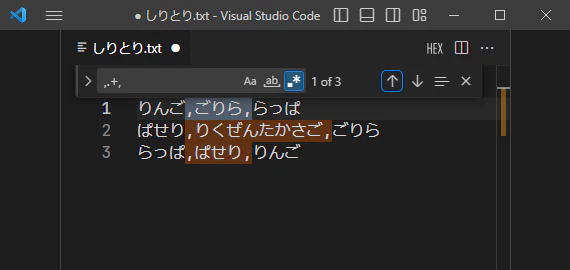
これならば、りんごに限らずりくぜんたかさご(陸前高砂)でもちゃんとヒットしていますね。
正規表現による置換の例
正規表現は置換に利用してこそ、大きな恩恵を感じられると思います。こちらについても少しだけご紹介します。
Visual Studio Codeでは検索窓の左側にある>の部分をクリックすると、置換窓が下に展開します。
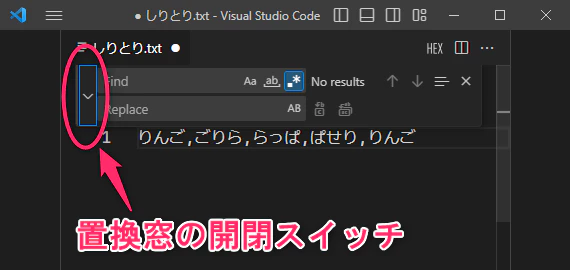
カンマ区切りを改行区切りにする
カンマ区切りの単語の羅列を用意します。
|
1 2 |
りんご,ごりら,らっぱ,ぱせり,りんご |
カンマで区切って、1行に1単語ずつになるように変形してみます。
置換文字列でも改行は\nで表せるので、単純にカンマをこのメタ文字で置き換えればOKです。
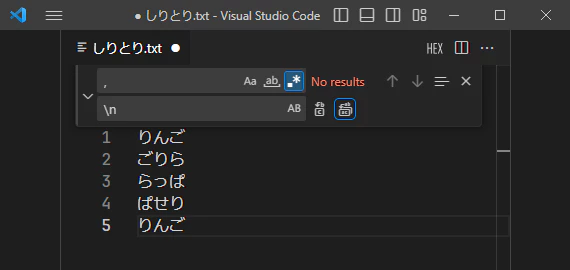
カンマ区切りの単語をダブルクォーテーションで囲う
ExcelのCSV形式は列ごとに文字列がダブルクォーテーションで囲われていますので、前述のシンプルなCSVを元にそれを再現します。
この場合、検索でヒットした文字列を置換先に引用する必要がありますが、正規表現置換では()と$1 $2($に数字が続く文字列)を用いて、いとも簡単に実現できます。
この場合は検索文字列に([^,]+)(,)?、置換文字列に"$1"$2を指定すれば実現できます。
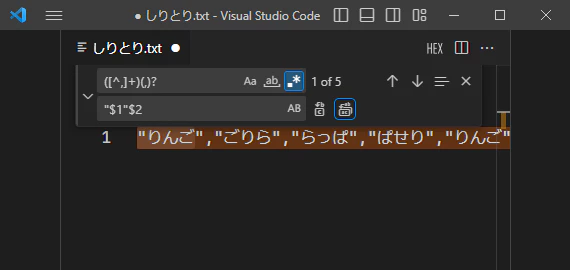
[]もメタ文字です。^がここでも出てきていますが、[]の中にある場合は先にでてきた『行の先頭』とは意味が異なります。まとめ
以上のような感じで、正規表現についてざっくり説明させていただきましたが、雰囲気は掴めましたでしょうか?
今回はあくまで初歩的な使い方にしか触れていませんが、正規表現の歴史は意外と長く、非常に奥深い機能があるので、まだまだ沢山の使い方があります。
ちなみに、一番最初に紹介したパターン例は何を表しているかというと、アルファベットの大文字と小文字と数字をそれぞれ少なくとも1文字以上含む、長さ10~20文字の文字列というよくあるパスワード書式の検証をするものです。流石にこれを自力で組むにはそこそこの経験値が必要ではありますが、逆にこのような複雑な条件であっても、短い文字列で表現できてしまうというのはすごい画期的だとは思いませんか?
正規表現は頭を使うので苦手な方も少なくないとは思いますが、昨今では話題のChatGPT等のAIに考えてもらうことだって可能です。そう考えると用法を知っていれば、利用する為のハードルはとても低いとも言えます。
ということで、情報化の現代社会において正規表現は一度学べば一生使えるスキルとも言われたり言われなかったりしますので、ぜひ積極的に活用してみてくださいね!😉
おしまい

